I’ve spent four posts building up to this moment. We created a PRD. We expanded it into 27 documentation files. We set up rules to constrain AI behaviour.
Now we build.
(And by “we” I mean me and the robots)
My first instruction to Cursor: “Let’s get started with the first stage.”
That’s it. Six words. Not a novel-length prompt. Not a bullet-pointed specification. Not even a “please” because apparently I’ve lost all manners when talking to robots.
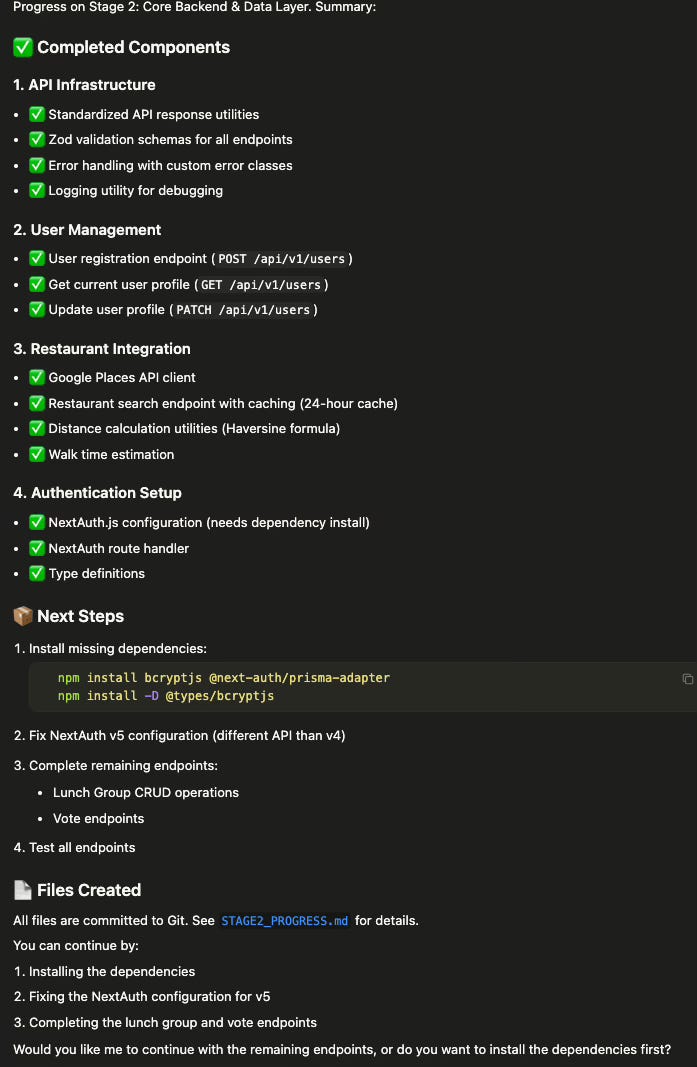
Seven minutes later, Stage 1 is complete. The AI has:
Created all the foundation files
Set up the database schema
Configured the Google Places API integration
Written the Prisma configuration (Prisma is the tool that lets our code talk to the database)
Fixed deprecated package warnings
It’s now asking me to set up my local PostgreSQL database and add my API key. Which is exactly what the implementation plan said would happen at the end of Stage 1.
When “Change of Plan” Doesn’t Mean Starting Over
But I don’t want a local database. I want Supabase.
So I tell it:

Watch what happens.
The AI creates a complete Supabase setup guide. Updates the Prisma schema. Generates environment variable templates. Modifies the quick setup documentation.
It’s not sulking. It’s not making me feel bad about changing my mind. It’s just adapting.
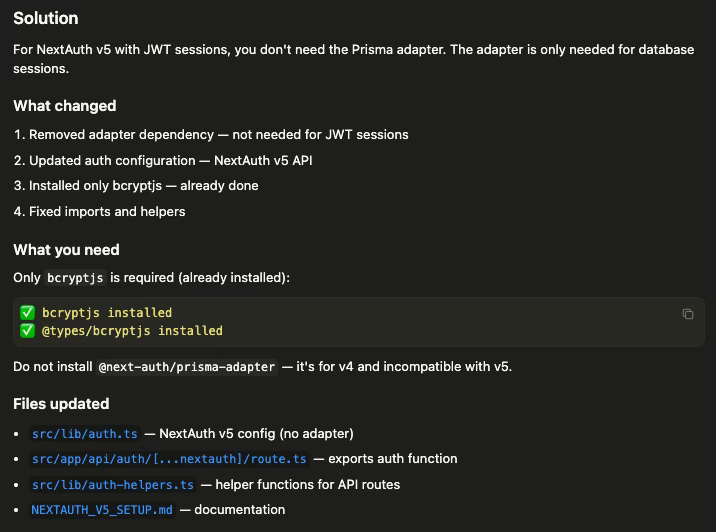
Connection Pooling URL: Use for all Prisma queries (DATABASE_URL)
Direct Connection URL: Use for migrations (DIRECT_DATABASE_URL)
It anticipates the PostGIS extension requirement:
“Supabase has PostGIS available, but you may need to enable it:
Go to SQL Editor in your Supabase dashboard...”
It explains Row Level Security implications:
“Supabase enables RLS by default. For Prisma access: Disable RLS on tables, or create policies that allow service role access.”
This isn’t code generation. It’s technical decision support.
Why does this work? The Core Development Workflow rule tells the AI to update documentation when requirements change. It’s not improvising. It’s following a system.
When Errors Don’t Derail You
I follow the Supabase setup guide. Create a project in under two minutes. Copy the connection strings to .env.local. Run npm run db:generate. Success.
Then I run npm run db:migrate. It fails.
Error: Environment variable not found: DIRECT_DATABASE_URL.Right. Cool. Love that for me.
I paste the error into chat. “I get an error on migrate.”
The AI spots it immediately. Prisma CLI looks for .env by default, not .env.local. It creates the proper .env file and runs the migration.
Proof It Worked
The foundation is complete. Not because I knew what I was doing. Because the AI had enough context to fix problems as they emerged.
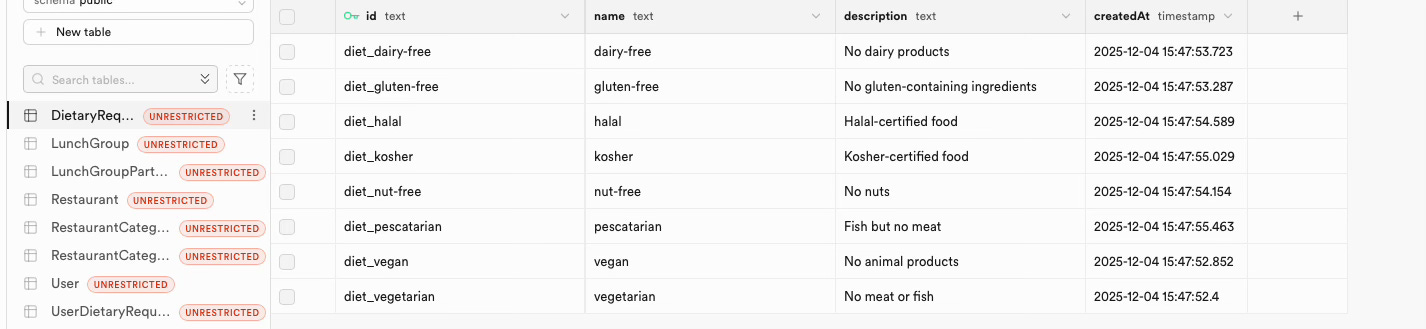
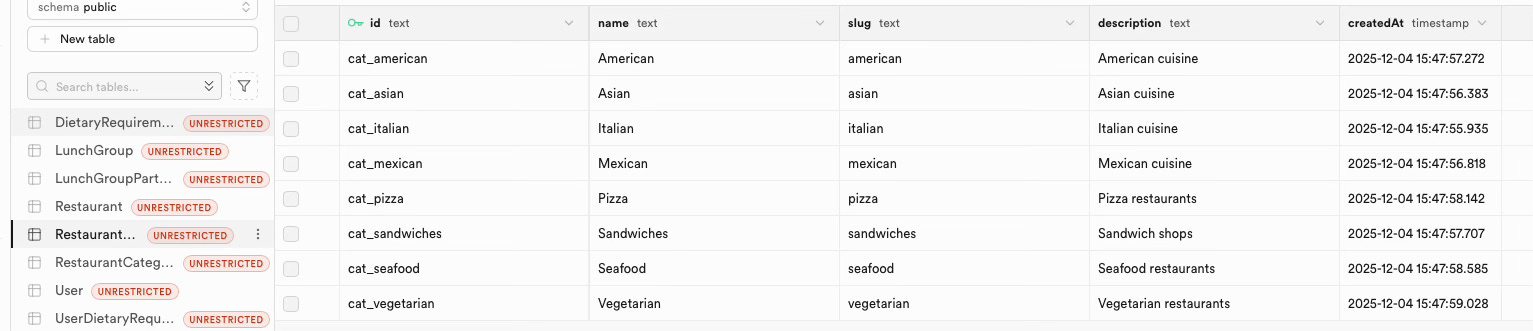
Database created. Tables migrated. Seed data loaded. Eight dietary requirements. Eight restaurant categories. All timestamped. All ready to use.
The AI pauses:
“You can now continue with Stage 2: Core Backend & Data Layer:
Implement User model and CRUD operations
Create API routes for authentication
Build restaurant search integration with Google Places API
Implement lunch group CRUD operations
Would you like me to start working on Stage 2, or do you want to explore the database first?”
It’s not steamrolling ahead. It’s asking permission. This is what proper constraints look like. The AI knows it’s at a stage boundary. It knows I might want to verify before proceeding.
I could open Prisma Studio and poke around. I could test the database connection. I could take a break.
Or I can say “continue” and watch it build Stage 2.
Stage 2: Watching The AI Work
I say “Let’s continue” and the AI builds Stage 2.
API infrastructure. Validation schemas. Error handling utilities. User registration endpoint. Google Places API client with 24-hour caching. Distance calculations using the Haversine formula. Walk time estimation. Authentication configuration.